DeepMind and Stanford University have brought out an AI tool for ascertaining truthfulness of information produced by large language models, such as GPT-4. What makes those AI models so wonderful is that they do make up facts, sometimes even in long sentences. The tool is now in use and is now able to measure how precise these models predict.
Here’s how it works: To begin with, LongFact was designed as a battery of questions set by DeepMind. This language model template questions 38 different topics on which live chatbots have to give long answers. Next, the SAFE AI device also is plugged in. SAFE is defined as a search engine Google uses for checking the facts in the LLM’s answers SAFE dissects the long answer into the separate facts and wants Google to give their answer for each fact. From the search outcomes, SAFE uses fact-checking to establish if it is accurate or not.
This will be a new means using which researchers will find out which LLMs are good at giving factual answers, mainly when responses are long.
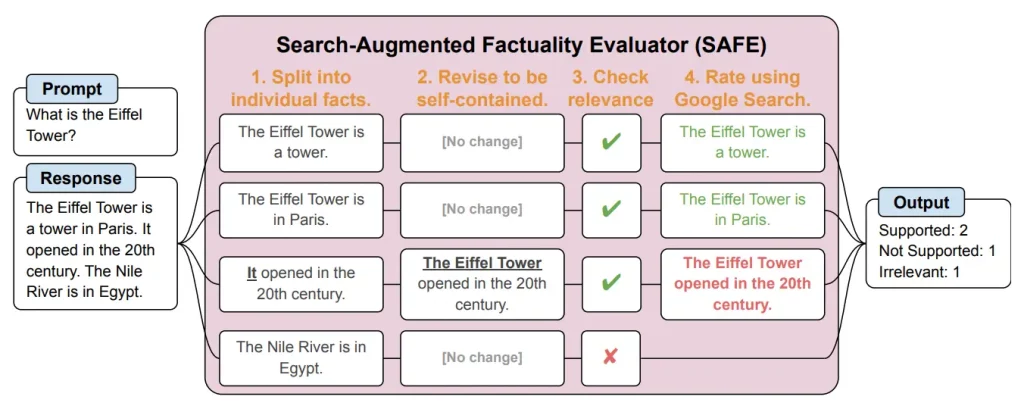
Researchers tested a new AI tool called SAFE to see how well it checks facts compared to humans. SAFE did well! It agreed with humans on most facts (72%) and even corrected them on some (76% of disagreements).
Another bonus? SAFE costs much less (20 times cheaper) than hiring people to check facts.
To measure how good AI models are at answering questions with facts, researchers use a scoring system called F1@K. This score considers two things: how many facts the answer has and how many of those facts are true. Imagine someone asks a question. F1@K would check if the answer gives enough facts (like you wanted) and if most of those facts are correct.
Which LLM is most factual?
Researchers tried to determine how good different AI models are at answering questions that involve facts. They used a Long Fact tool to ask questions and another tool called SAFE to verify the answers.
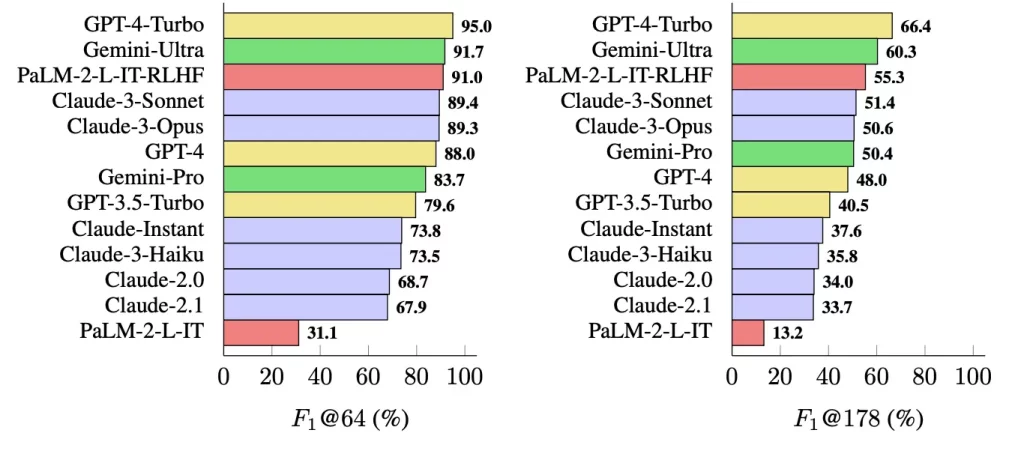
Among these models, GPT-4-Turbo performed the best job in providing accurate answers in long responses. It was in first place, followed by Gemini-Ultra and another model called PaLM-2-L-IT-RLHF. This indicates that bigger AI models are usually more successful at producing accurate facts.
A metric called F1@K is used by researchers to determine the ability of AI models to answer questions with facts. Don’t worry about how it works exactly, but just know it considers two things: how many true statements the answer contains and how many of those statements are accurate.
SAFE is a new tool that provides a way to assess how reasonable AI models are. This way is quicker and cheaper than hiring individuals to do this task. However, it should be mentioned that SAFE is based on the data retrieved from Google searches, so the reliability of such search results determines how well SAFE performs.
The team that made SAFE launched it for everyone’s use. This tool can help to achieve even more precise factual answers by AI models. This may also be used as a checking up feature of AI models where they check their own answers before showing them to people.
This could be a good thing for OpenAI, the company responsible for GPT-4 creation. Finally, this outcome confirms that GPT-4 surpassed Gemini in another test of competencies.








